

Jonathan Tennenbaum – 5 de junho de 2020
O aprendizado profundo da IA obteve ganhos no reconhecimento e tradução de imagens, mas os erros ainda destacam falhas flagrantes
 Modelo de uma máquina de Turing por Mike Delaney. Fonte: Wikimedia
Modelo de uma máquina de Turing por Mike Delaney. Fonte: Wikimedia
Esta é a segunda parte de uma série. Leia a parte 1 aqui.
A raiz final da estupidez dos sistemas de IA, eu argumento, reside em seu caráter estritamente algorítmico. A IA, conforme entendida atualmente, é baseada em sistemas de processamento digital que executam operações numéricas binárias passo a passo, de acordo com conjuntos fixos de algoritmos, a partir de uma matriz de entradas numéricas.
Alguns podem se opor a essa caracterização, apontando que os sistemas de IA podem mudar constantemente suas próprias “regras” – reprogramando-se, por assim dizer. Isso é verdade; mas a auto-reprogramação deve seguir algum algoritmo.
O mesmo se aplica aos processos pelos quais o sistema reage a várias entradas. Em última análise, cada sistema de IA é governado por um conjunto de regras e procedimentos incorporados ao design do sistema e que permanecem inalterados durante sua operação, desde que o sistema permaneça intacto.
Alan Turing, um dos grandes pioneiros da inteligência artificial, conseguiu dar uma definição precisa para a noção geral de “algoritmo” ou “procedimento mecânico”, que engloba todos os sistemas de IA que poderiam ser realizados com base em hardware digital. Turing demonstrou que qualquer sistema desse tipo é matematicamente equivalente a uma entidade abstrata agora conhecida como “máquina de Turing”.
Além disso, existe uma máquina de Turing única e universal que pode simular qualquer outra, quando o projeto da última é inserido em forma codificada adequadamente. Com base nisso, pode-se investigar as possibilidades e limitações teóricas dos sistemas de IA por métodos matemáticos (velocidade e outros aspectos físicos sendo deixados de lado).
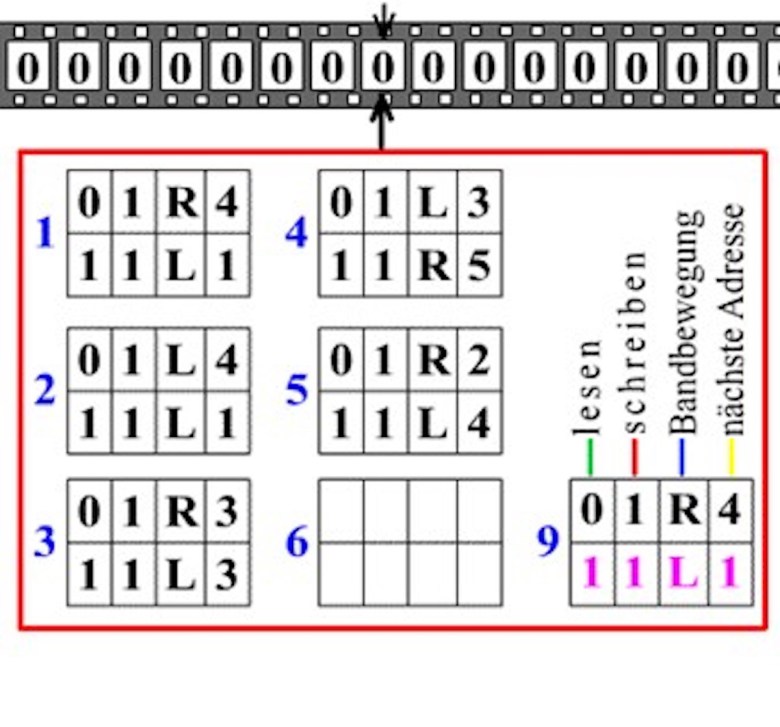
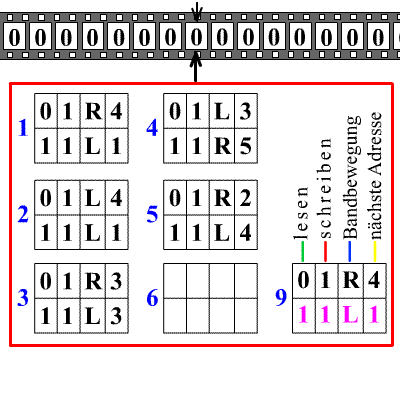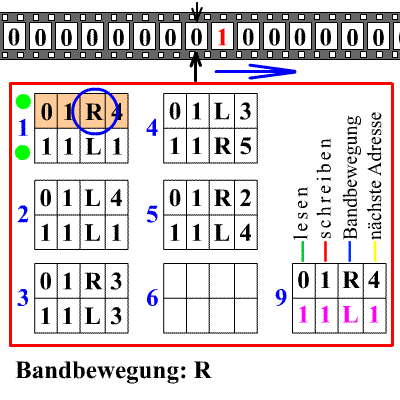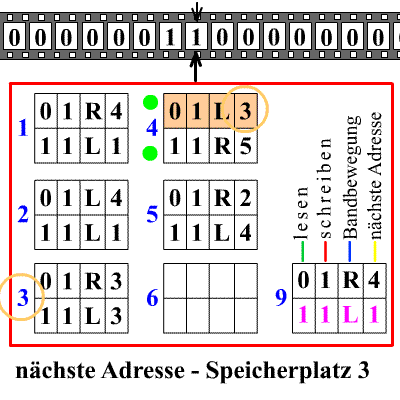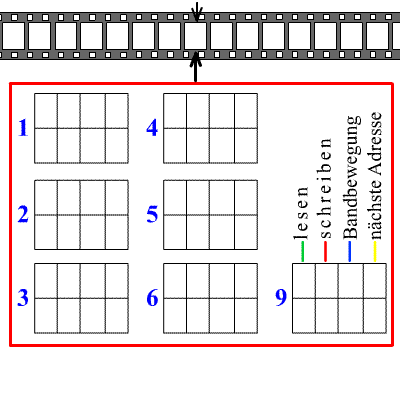
O diagrama mostra uma fita sem fim com quadrados nos quais zero ou um está escrito. A máquina tem um cabeçote que pode ler, apagar ou imprimir um zero ou um, e mover a fita um passo para a direita ou para a esquerda. Os retângulos numerados abaixo contêm as regras (programa) da máquina.
A regra 1 diz, por exemplo: se você leu um zero, apague-o e imprima um um, mova a fita um espaço para a direita e vá para a regra 4; mas se você ler um, deixe-o inalterado, mova a fita um espaço para a esquerda e aplique a regra 1 novamente. A máquina começa na regra 1 com alguma sequência de zeros e uns escritos na fita. Também pode haver uma regra que diga à máquina para parar.
Você pode ver uma animação (bastante lenta), mostrando como funciona uma máquina de Turing.
{kind=link}
Não importa o quão sofisticado um sistema de IA possa ser, não importa como podemos combinar sistemas de IA de várias maneiras na interação de arquiteturas hierárquicas paralelas e automodificáveis, o que acabamos sempre se resume a uma máquina de Turing operando sob um conjunto fixo de regras de programação.
A estupidez é incorporada aos sistemas de IA, tanto nos níveis mais baixos quanto nos mais altos.
No nível micro, temos bilhões de elementos de comutação individuais nos chips IC, cada um dos quais realiza suas transições on-off de maneira 100% determinística e rigidamente mecânica. Eles são 100% estúpidos. Isso é o que eles foram construídos para fazer. Eles dificilmente se assemelham às células vivas – neurônios e células gliais, embutidas no sistema intersticial do cérebro – que constituem o substrato para os processos mentais humanos.
No nível macro, o comportamento de um sistema de IA é subserviente às suas regras de programação. Não tem como mudá-los por dentro. Ele interpreta e reage a todos os eventos de acordo e continuará a fazê-lo, mesmo quando eles levarem ao desastre.
Assim, todos os sistemas de IA baseados em hardware digital são inerentemente estúpidos, mesmo quando manifestam um comportamento inteligente, de acordo com os dois primeiros dos meus quatro critérios de estupidez conforme apresentados na parte 1 desta série. Aqui estão esses dois novamente, para lembrá-lo:
S 1. Adesão continuada aos procedimentos, hábitos, modos de pensar e comportamento existentes, combinada com uma incapacidade de reconhecer sinais claros de que estes são inadequados ou mesmo desastrosos no caso concreto dado. Adesão rígida à experiência passada e aprendizado mecânico diante de situações que exigem um novo pensamento. Pode-se falar de comportamento cegamente “algorítmico” no sentido mais amplo.
S 2. Incapacidade de “pensar fora da caixa”, de olhar para o quadro geral, de pular mentalmente para fora do processo no qual está envolvido e fazer perguntas abrangentes como: “O que estou realmente fazendo?” e “Faz sentido?” e “O que realmente está acontecendo aqui?”
A seguir, vamos examinar alguns exemplos de como a estupidez dos sistemas de IA se manifesta em seu desempenho prático.
Aprendizado profundo
Os chamados sistemas de aprendizado profundo desempenham um papel dominante nas aplicações de IA hoje. A ideia básica pode ser conhecida por muitos leitores, mas vou resumi-la brevemente aqui.
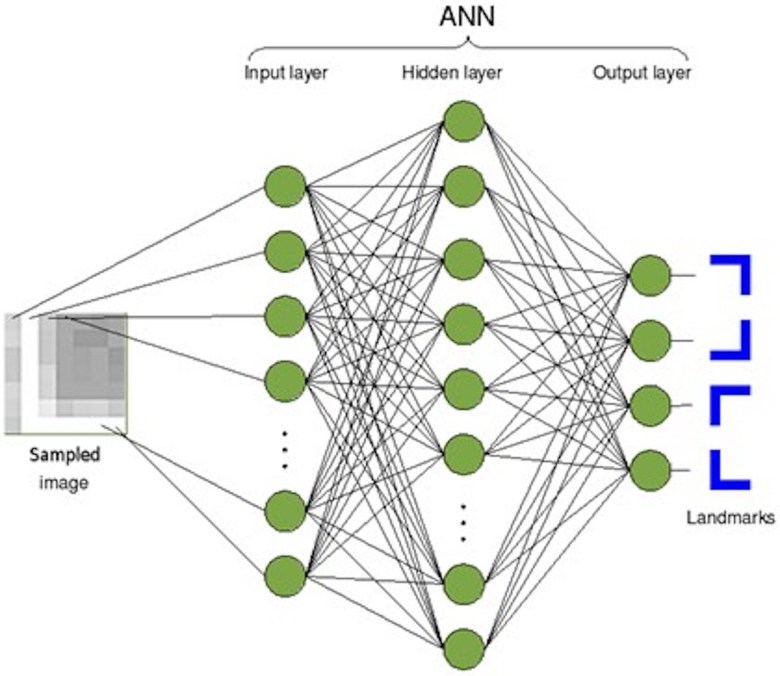
O aprendizado profundo é baseado no uso de redes neurais artificiais multicamadas. As redes são compostas por camadas de nós eletricamente interconectados (“neurônios artificiais”), cada um dos quais recebe entradas dos nós da camada anterior e calcula uma saída que vai para os nós da camada seguinte. As entradas para cada nó de outros nós recebem pesos relativos, que são ajustados no curso de um processo de “aprendizagem”.
A primeira camada de nós (a camada à esquerda no diagrama) recebe entradas externas: por exemplo, pixels de uma imagem a ser identificada. A ideia é, ajustando os pesos relevantes, fazer com que os nós em cada camada respondam a padrões relevantes nos dados da camada anterior, para que os nós na camada final nos dêem a resposta desejada.
Por exemplo, podemos querer que um desses nós finais seja ativado se a imagem for um círculo; outro nó, se a imagem for um quadrado.
Usando um algoritmo extremamente engenhoso, pode-se fazer com que essa rede ajuste gradualmente seus parâmetros internos por si mesma, quando apresentada a um grande número de pares de entradas e respostas corretas (neste exemplo, imagens corretamente identificadas), de forma a fornecer respostas cada vez melhores para entradas arbitrárias – pelo menos no sentido estatístico.
Pode-se descrevê-lo como um método altamente sofisticado de ajuste de curva.
Cisne negro e caixa preta
A abordagem de aprendizado profundo alcançou sucessos surpreendentes. Mas também há problemas.
Como o processo de otimização é de natureza estatística, ele tende a fornecer as respostas corretas apenas para entradas semelhantes às que ocorreram com frequência nos conjuntos sobre os quais foi treinado. Para entradas raramente encontradas, os resultados podem ser extremamente errôneos. O chamado fenômeno do Cisne Negro representa um grande desafio para o desenvolvimento de veículos autônomos, que podem enfrentar uma grande variedade de situações inusitadas.
Igualmente sério é o problema da caixa preta: as redes de aprendizado profundo, como as usadas para identificação de imagens, têm 10 ou mais milhões de parâmetros internos. Os valores desses milhões de parâmetros saíram de um processo de treinamento envolvendo grandes quantidades de dados.
A rede tornou-se assim uma “caixa preta”: a função de entrada-saída da rede é matematicamente tão complicada que não temos como prever ou explicar o comportamento do sistema em geral.
A identificação visual de objetos, que está sendo empregada em toda parte em grande escala, é um bom exemplo.
Apesar das melhorias constantes, esses sistemas continuaram a ser atormentados por casos de identificação totalmente falsa de objetos, do tipo que os humanos praticamente nunca fariam. Além disso, tais erros podem ser provocados deliberadamente pelos chamados exemplos adversários, que se tornaram um novo campo de pesquisa em IA.
Aqui (cortesia de Dan Hendrycks) estão alguns erros no reconhecimento de imagem pelo sistema de reconhecimento de imagem AI ResNet-50 – uma rede neural de aprendizado profundo com 50 camadas treinadas profundamente em mais de um milhão de imagens.
“banana”

“ônibus escolar”

A IA vê a imagem como uma “banana”. Fonte: Wikimedia
Aqui está outro exemplo contraditório do LAB de Ciência da Computação e Inteligência Artificial do MIT, no qual uma pequena perturbação da imagem faz com que um sistema de reconhecimento de imagem de IA produza uma interpretação extremamente errônea.

Em um exemplo típico de adversário, a imagem é ligeiramente modificada de uma maneira que é quase imperceptível para um espectador humano – mas faz com que o sistema de IA produza uma resposta totalmente diferente.
O fenômeno dos exemplos adversários demonstra que o que esses sistemas “aprenderam” a fazer difere fundamentalmente de como os seres humanos reconhecem os objetos. Em muitos casos, os sistemas detectam uma espécie de textura na imagem – e não a forma (Gestalt) que o ser humano percebe. Exemplos adversários análogos podem ser produzidos para sistemas de reconhecimento de voz.
Geralmente, o que é chamado de “aprendizagem” nos sistemas de inteligência artificial existentes tem pouco ou nada a ver com a maneira como os seres humanos realmente aprendem. Na melhor das hipóteses, pode-se encontrar analogias com memorização mecânica irracional ou técnicas skinnerianas de modificação comportamental às quais nenhuma pessoa inteligente se submeteria.
Os exemplos adversários tornaram-se uma fonte muito séria de preocupação, principalmente nos usos militares (por exemplo, sistemas de identificação de alvos) e de segurança baseados em IA. Veja por exemplo “Como os ataques adversários podem desestabilizar os sistemas militares de IA” e “A inteligência artificial militar pode ser fácil e perigosamente enganada.”
Traduzindo sem entender
Um segundo exemplo é a tradução automática. Aqui, a abordagem de aprendizado profundo alcançou sucessos extraordinários, em grande parte graças ao seu gigantesco banco de dados e melhorias constantes. Mas o problema da estupidez permanece.
O Google Tradutor é um bom exemplo. O Google Tradutor opera com um vasto banco de dados em constante crescimento de centenas de milhões de documentos e passagens de texto com traduções emparelhadas produzidas por humanos.
Entre outras coisas, o Google Tradutor utiliza o banco de dados multilíngue das Nações Unidas, que inclui mais de 1,5 milhão de pares de documentos alinhados nos seis idiomas oficiais da ONU, e o banco de dados multilíngue da Comissão Européia. Traduções de frases são geradas, correlacionadas com frases traduzidas por humanos e otimizadas estatisticamente para produzir a “melhor” tradução.
Desnecessário dizer que o procedimento do Google Tradutor envolve nada além de manipulações com séries de zeros e uns de sua entrada e de seu banco de dados. Teoricamente, se uma pessoa vivesse o suficiente – milhares de anos, provavelmente – e tivesse paciência suficiente para realizar os procedimentos de cálculo, então essa pessoa poderia traduzir textos (em formato digitalmente codificado) do suaíli para o tibetano sem saber uma palavra de qualquer um dos idiomas.
Assim, o que o Google Tradutor faz é basicamente uma forma (mais ou menos) bem-sucedida de trapaça: traduzir textos sem entendê-los. A falta de capacidade de compreensão é uma forma de burrice (S 4).
A estupidez da tradução automática baseada em Deep Learning geralmente produz resultados hilários. Eu me diverti alimentando textos chineses contendo 成语 (chengyu) – expressões idiomáticas tradicionais, principalmente de quatro caracteres – em vários serviços de tradução online.
Por exemplo, o chengyu 马齿徒增 (mǎchǐtúzēng), literalmente “dentes de cavalo, inutilmente, crescem”, poderia ser traduzido – deixando para trás o humor, a ironia e o ritmo – como: “envelhecer sem realizar muito”. Incorporado em uma frase adequada, este chengyu pode fazer com que os tradutores automáticos enlouqueçam:
平心思量,一年来马齿徒增而事业无成,也只能忍气吞声当牛做马了。Tradutor do Google: “Se você pensar nisso por um ano, seus dentes vão crescer e sua carreira vai fracassar.”
Como costuma acontecer, a saída do tradutor de máquina pode ser instável. Se você inserir a frase mais de uma vez, poderá obter traduções diferentes.
Tradutor do Google (uma segunda vez): “Pensivamente, no ano passado houve um aumento no número de dentes e nenhum sucesso em suas carreiras.”
Tradutor do Baidu: “Acho que no ano passado o número de cavalos aumentou em vão e a carreira deles não teve sucesso. Eu só posso suportar ser um boi e um cavalo.”
Tais exemplos tornam óbvio que os sistemas de tradução de IA, pelo menos do tipo atualmente existente, não têm acesso ao significado per se. Eles são 100% burros nesse sentido (S 4).
A seguir vem a Parte 3: Bom senso no ajuste de curvas
Jonathan Tennenbaum recebeu seu PhD em matemática pela Universidade da Califórnia em 1973 aos 22 anos. Também físico, linguista e pianista, ele foi editor da revista FUSION. Ele mora em Berlim e viaja frequentemente para a Ásia e outros lugares, prestando consultoria em economia, ciência e tecnologia.
Fonte: https://asiatimes.com/2020/06/algorithm-approach-limits-artificial-intelligence/
Está sendo uma série boa!